Linux is a system full of commands where each one plays an essential role in the behavior of certain tasks, whether they are user, object or support management, each command has its participation in Linux and one of these commands is Sed of which We will talk in TechnoWikis in details..
What is the sed command in Linux
The sed command is literally a flow editor which we can use in order to modify works on the text with basic functions in an input flow either from a file or input from a pipeline if applicable.
Unlike other text editors , with sed it is possible to filter text in a pipeline as we go over the selected content.
Advantage
The advantages of using sed on Linux are:
- We are able to replace text
- We can remove lines from the text
- Allows you to modify or preserve an original file
The general syntax for using sed is as follows:
sed OPTIONS ... [SCRIPT] [INPUT_FILE ...]
We will learn some ways to use this command on Linux.
1. How to use SED command in Linux
Basic use of sed
For this example we are going to use "echo" to see how the sed command can replace part of the entered text, we enter:
echo solvitic | sed 's / vitic / vetic /'
In this case we are telling sed to replace the word “vitic” with “vetic”, when pressing Enter this will be the result:
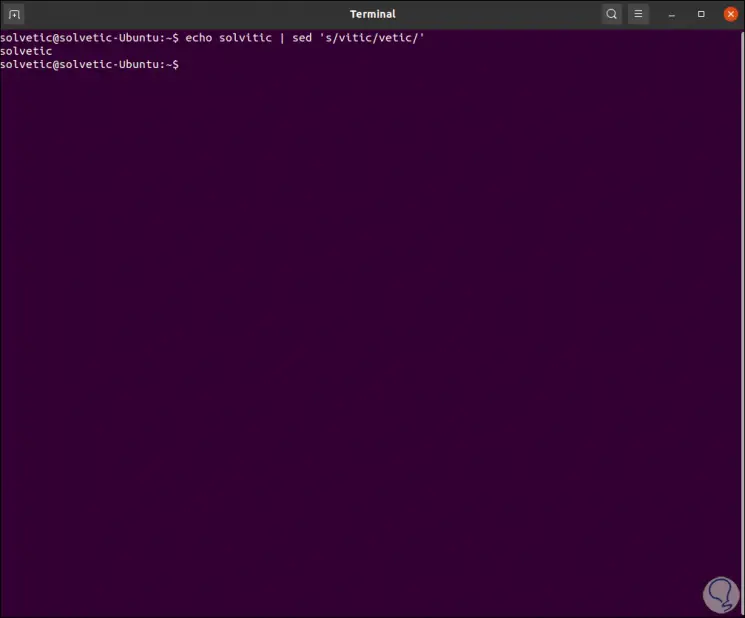
We see that the change is automatic.
2. Selecting text with the SED Linux command
Step 1
In this case we will have a text file which is hosted on the desktop:
Now we will use the following line:
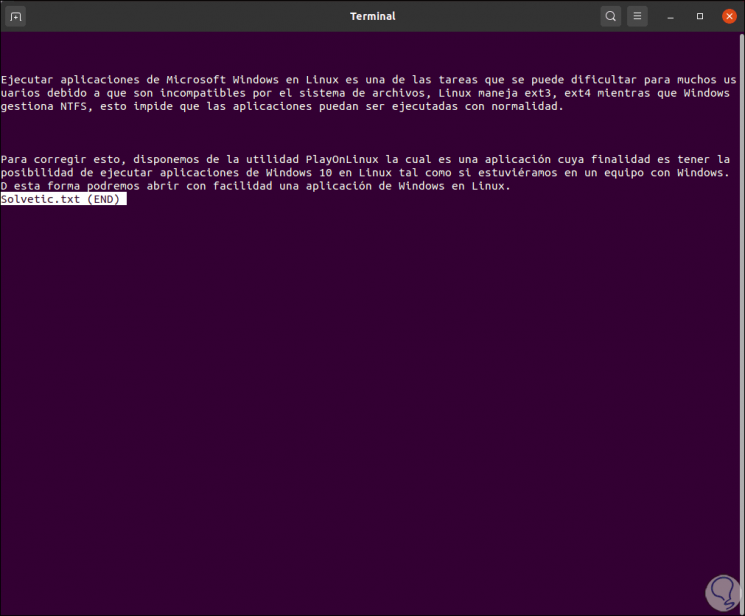
less TechnoWikis.txt
Step 2
When pressing Enter this will be the result:
With sed it is possible to select some lines of the file, for this we must indicate the initial and final lines of the range to select, for example, if we want to extract lines two to seven we execute:
sed -n '2,7p' TechnoWikis.txt
Step 3
We will see the following:
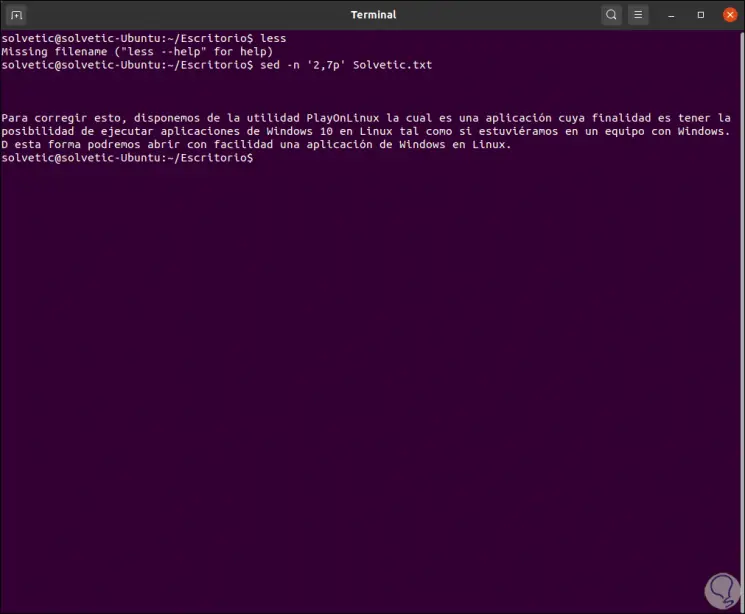
We must bear in mind the comma in the ranges to be assigned (2,7), the parameter p indicates it means "print matching lines", with this the sed command will print all the lines of that range and the -n (quiet) option takes care of not to display text that does not match that range..
Step 4
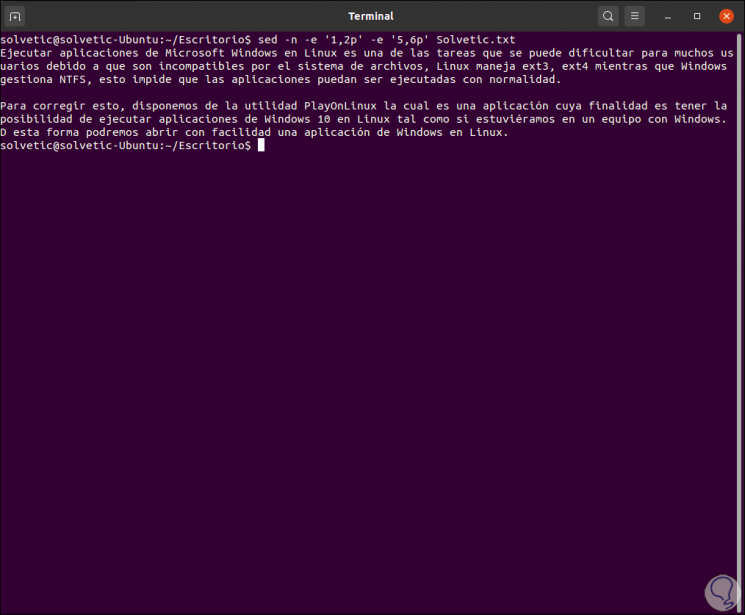
We can use the parameter -e (expression) in order to make multiple selections, for example:
sed -n -e '1,2p' -e '5,6p' TechnoWikis.txt
Step 5
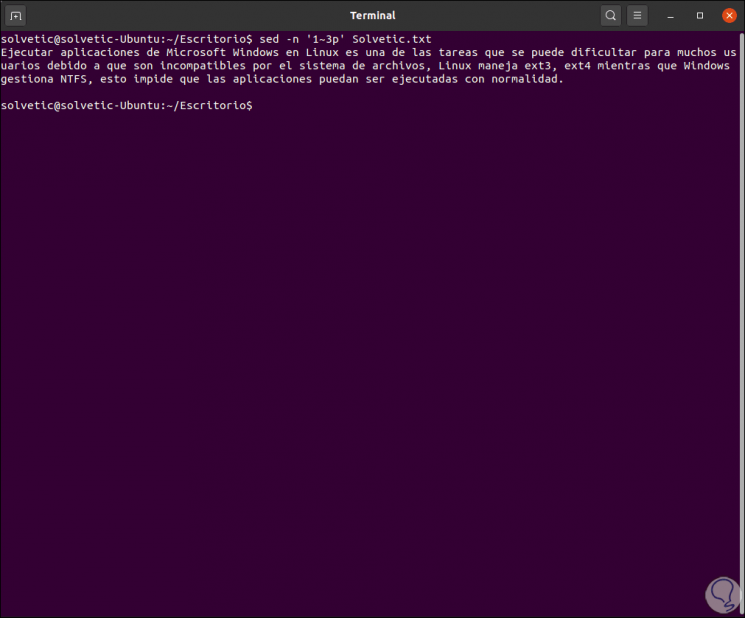
With sed it is possible to select the starting line, then we indicate which should be traversed in the file and that it prints the alternate lines, for example, we enter:
sed -n '1 ~ 3p' TechnoWikis.txt
In this case the first number refers to the start line and the second number tells sed which lines after the start line will be displayed:
Step 6
Another use of sed is the ability to select lines in which the matching text patterns are, this if we do not know where the line number originates from, we can execute the following:
sed -n '/ ^ Run / p' TechnoWikis.txt
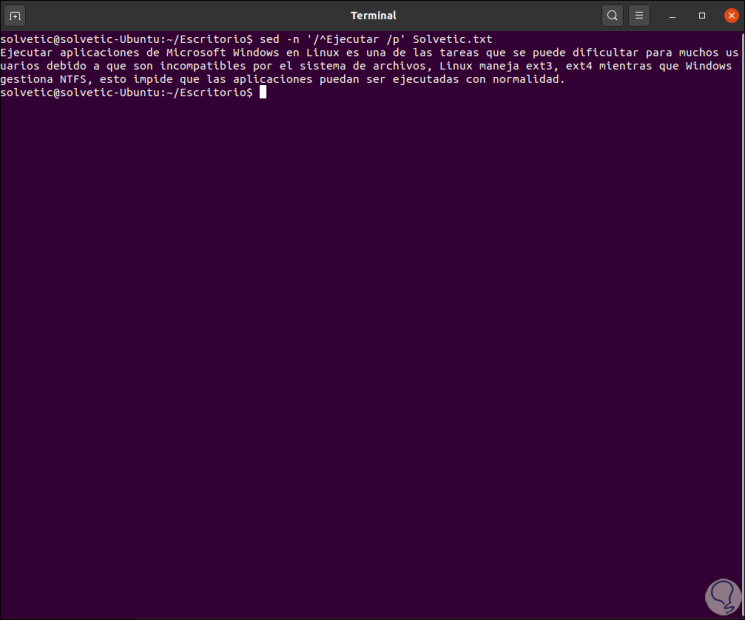
We will see the lines that begin with that term.
3. How to create replacements with SED Linux
Step 1
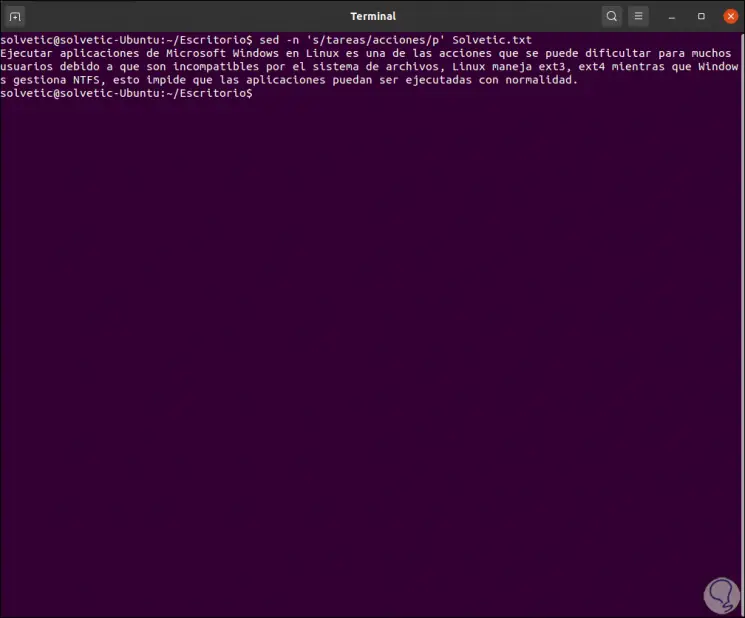
In the basic part we saw how to replace text using sed, there we used the -s (substitution) parameter. Then the first string indicates the search pattern and the second refers to the text with which it will be replaced.
sed -n 's / tasks / actions / p' TechnoWikis.txt
In this example we replace "tasks" with "actions":
Step 2
With the parameter p sed it stops automatically after the first match, to perform a global search and make the change in general we must add "g":
sed -n 's / tasks / actions / gp' TechnoWikis.txt
If we want it to be case insensitive, we will add the "i":
sed -n 's / tasks / actions / gpi' TechnoWikis.txt
Step 3
It is possible to create restrictions on replacements only to certain sections of the file, first of all we list the lines to be analyzed:
sed -n '1,3p' TechnoWikis.txt
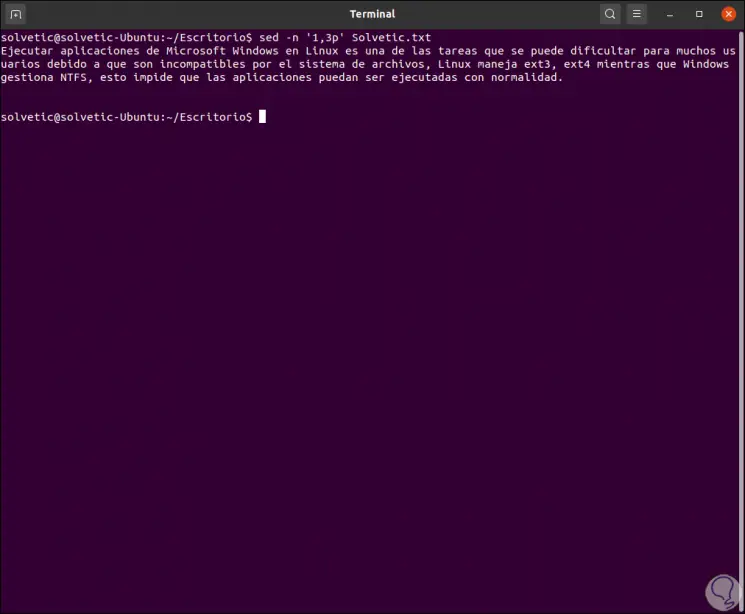
Step 4
Let's see the following, we can find where there are two spaces and replace them with one:
sed -n '1.3 s / * / / gp' TechnoWikis.txt
The asterisk (*) represents zero or more of the previously selected character.
Step 5
It is possible to reduce the search pattern to a single space with the following command:
sed -n '1.3 s / * / / gp' TechnoWikis.txt
We see the difference in the results:
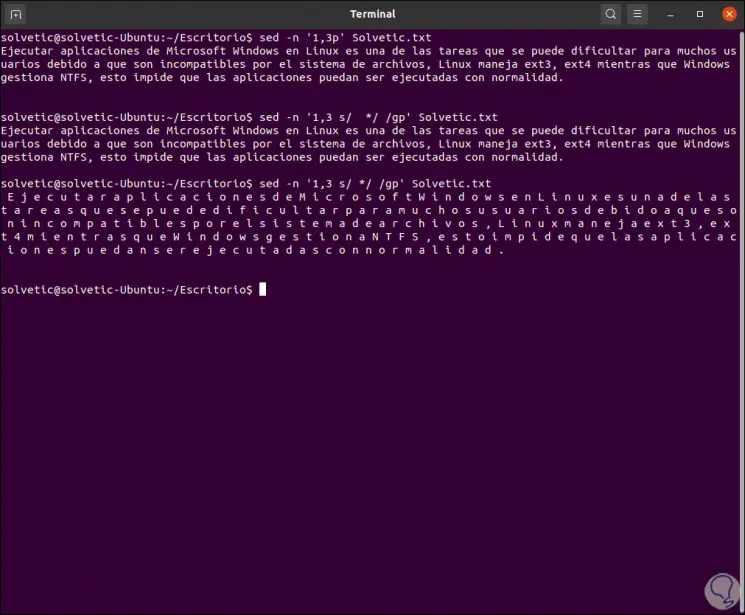
In the latter case, the asterisk matches zero or more of the previous character, this makes each non-space character look like a "zero space" applying the command..
Step 6
To make two or more substitutions simultaneously we execute:
sed -n -e 's / executed / applied / gip' -e 's / tasks / actions / gip' TechnoWikis.txt
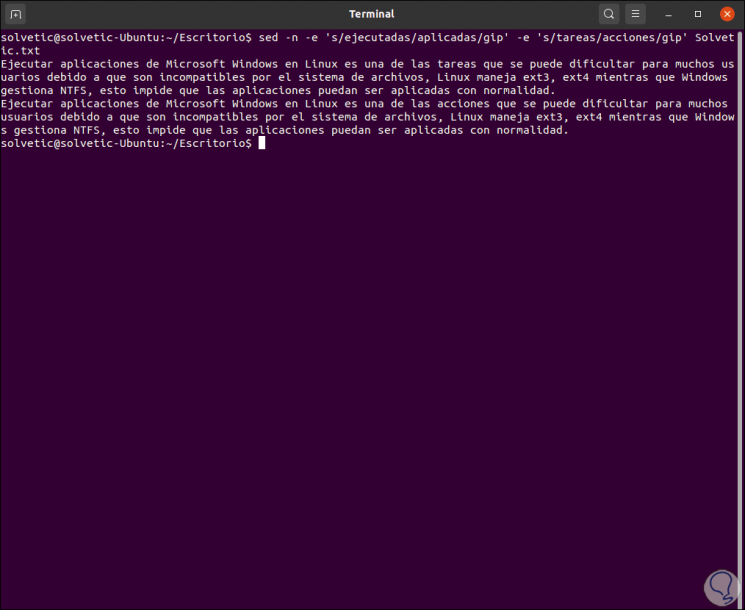
4. SED replacement options on Linux
We can also use sed to extract file names from the system, for this case we must bear in mind that each object must match a search pattern (subexpressions) which can be numbered (up to a maximum of nine elements).
Step 1
These numbers can then be used to reference specific subexpressions.
The subexpression must be enclosed in parentheses [()] and the parentheses must be preceded by a backslash (\) so that they are not detected as a normal character, for example:
sed 's / \ ([^:] * \). * / \ 1 /' / etc / passwd
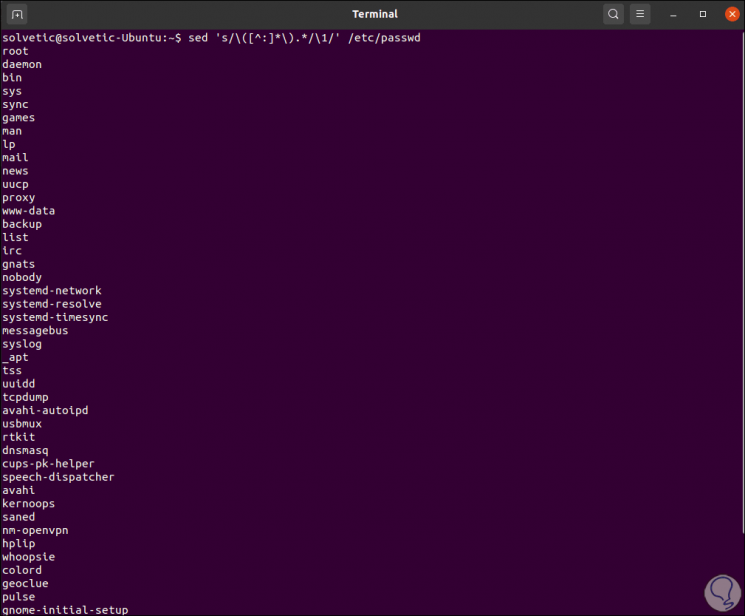
The variables used in this command are
- sed 's /: indicates the sed command and the start of the replacement expression.
- \ (: enclose the subexpression, preceded by a backslash
- [^:] *: is the first subexpression of the search term which contains a group between brackets, the caret sign (^) means "no" when used in a group, that is, any character other than a colon
- \): The closing parenthesis [)] with a backslash
- . *: is the second search subexpression which indicates "any character and any number of these".
- / \ 1: is the replacement part of the expression which contains a number 1 preceded by a backslash (\) and indicates that the text matches the first subexpression
- / ': terminate the sed command
Step 2
With the previous command we have searched for any character string that does not contain a colon, because each line of the / etc / passwd file starts with the username ending in a colon. We can substitute that value isolating the username with the following command:
sed 's / \ ([^:] * \) \ (. * \) / \ 2 /' / etc / passwd
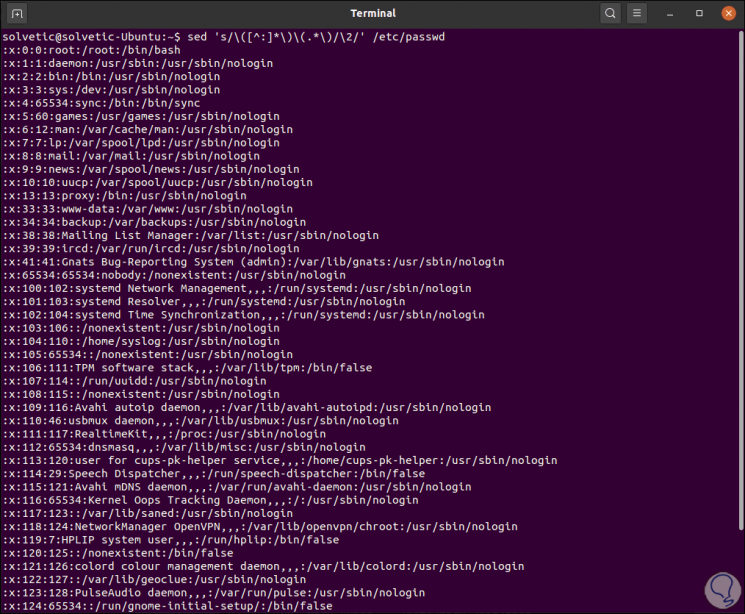
Step 3
We can display only the usernames with the following command:
sed 's /:.*// "/ etc / passwd
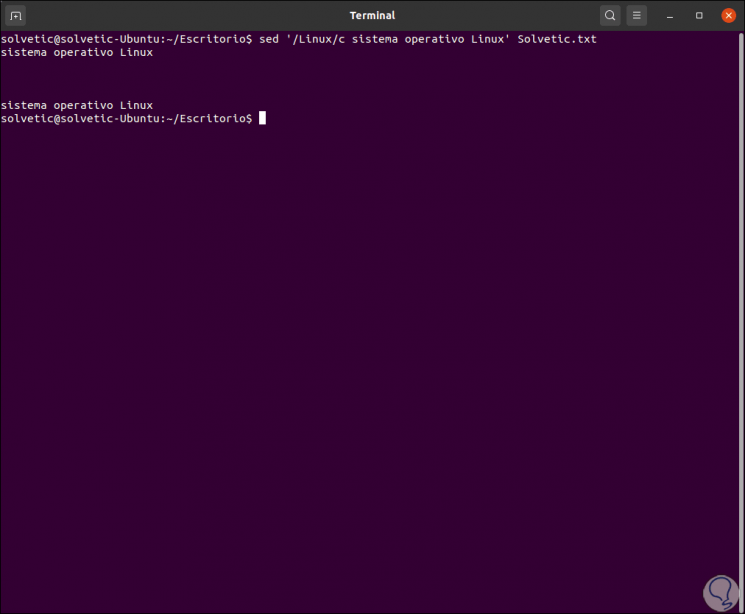
Another option with sed is to use the c (cut - cut) parameter to replace text in a file, for example:
sed '/ Linux / c Linux operating system' TechnoWikis.txt
5. Insert lines and text with SED in Linux
Step 1
Another task to use with sed is to insert new lines and text in a file, in this case we have the following data:
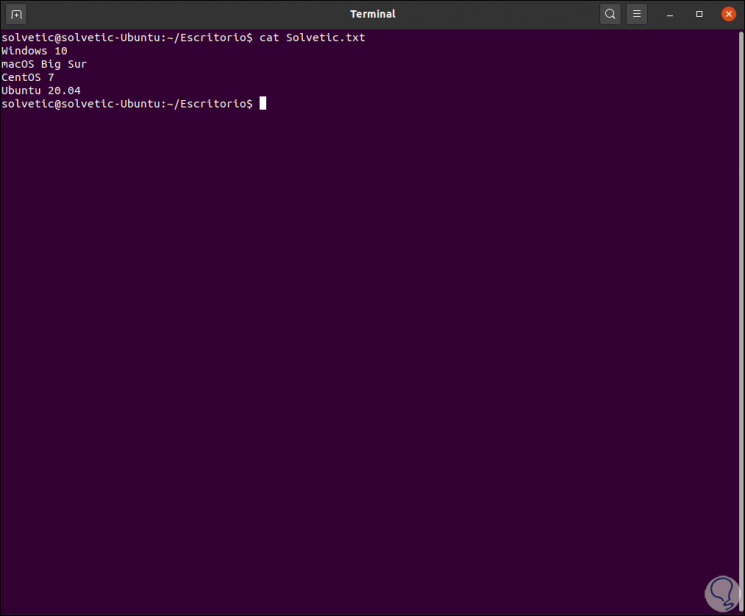
Step 2
We can insert a new line specifying below which it will be inserted:
sed '/ Ub / a -> Inserted!' TechnoWikis.txt
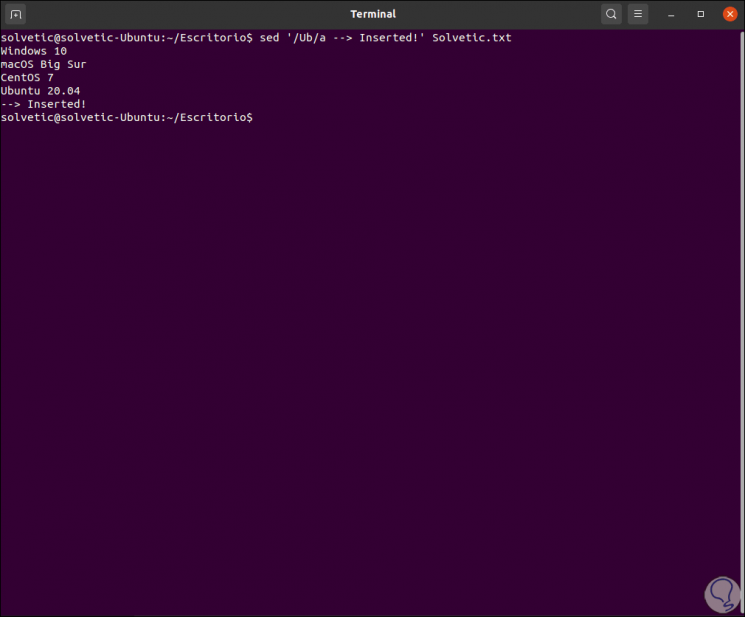
Step 3
It is also possible to use the Insert (i) command in order to insert a new line above the match:
sed '/ Wi / i -> Inserted!' TechnoWikis.txt
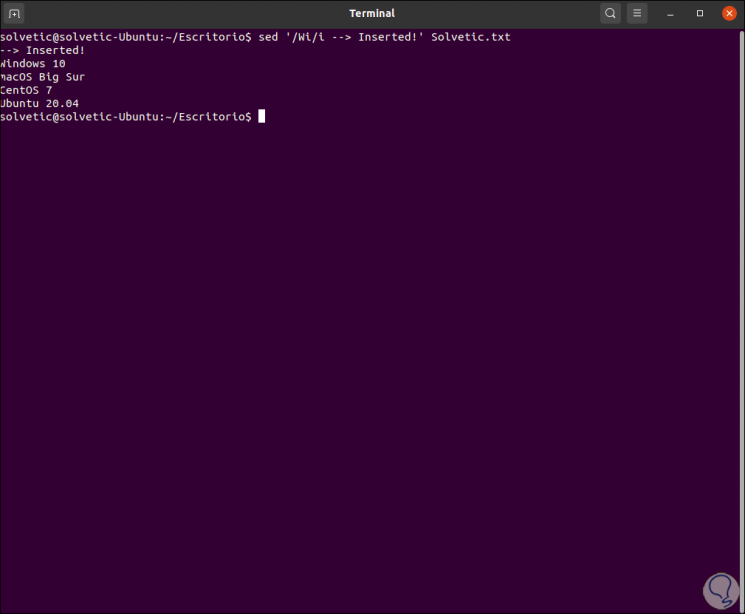
Step 4
We can make use of the ampersand sign (&) in order to add new text to a matching line in the file, we execute:
sed 's /.*/--> Inserted & /' TechnoWikis.txt
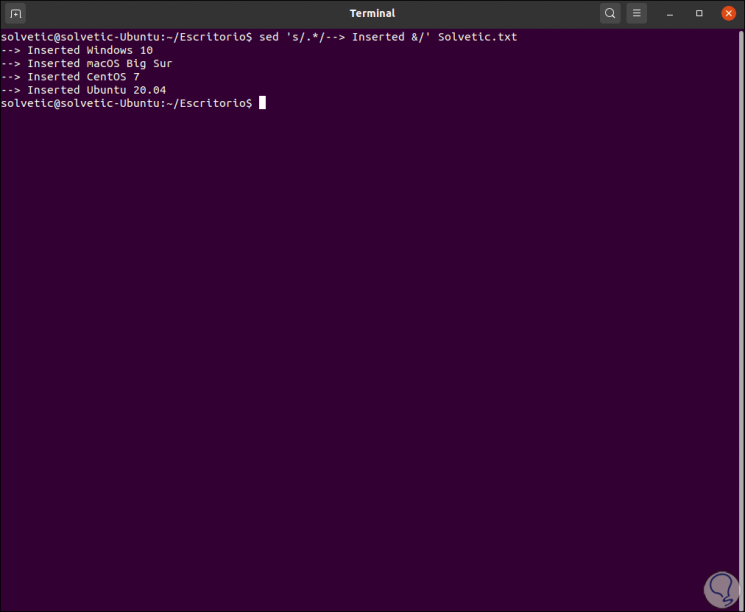
6. How to delete a line with SED Linux
For this case we must use the parameter d (delete), to delete for example the second line we execute:
sed '2d' TechnoWikis.txt
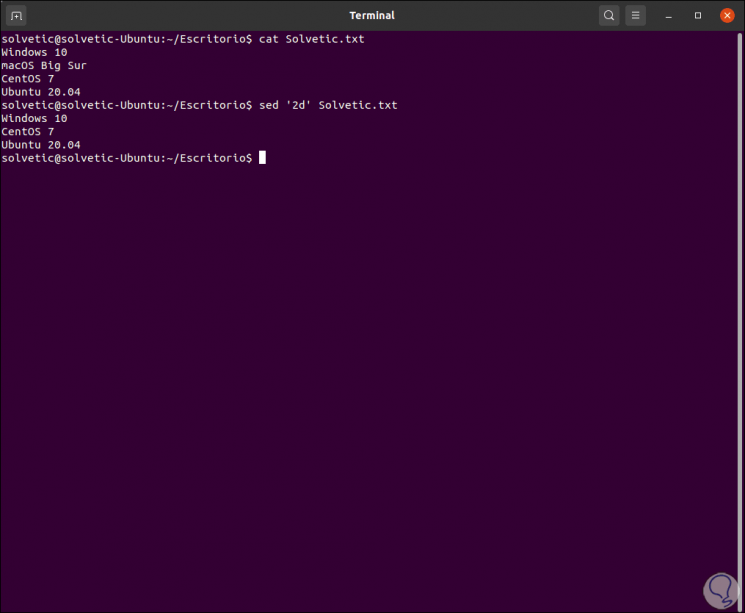
We can remove a range if necessary:
sed '1,4d' TechnoWikis.txt
To remove lines outside of a range, we must use an exclamation point (!) In the following way:
sed '2,4! d' TechnoWikis.txt
7. How to save changes with SED in Linux
Step 1
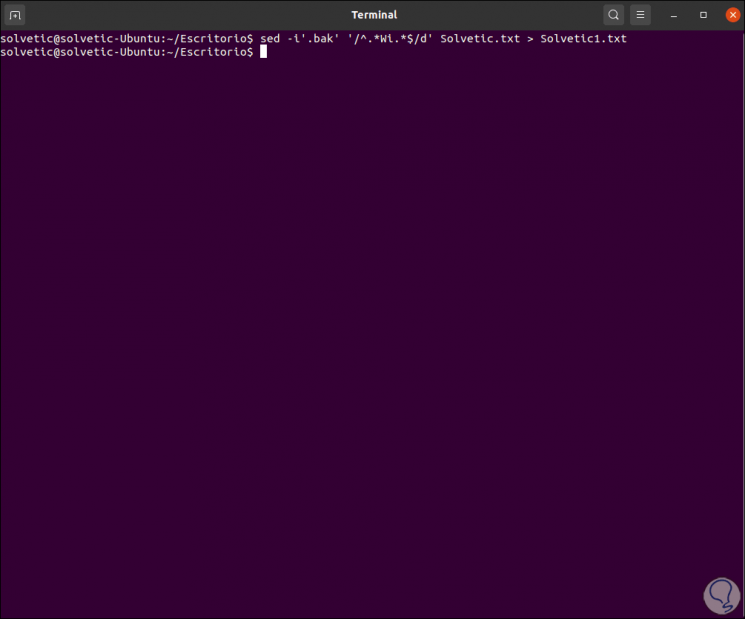
To apply the changes made, it is possible to use the In-place (-i) option so that sed write the changes to the original file, but for greater security we can add a backup extension as follows (we have backed up the lines containing the word Wi):
sed -i'.bak '' /^.*Wi.*$/d 'TechnoWikis.txt
We list the content:
cat TechnoWikis.txt.bak
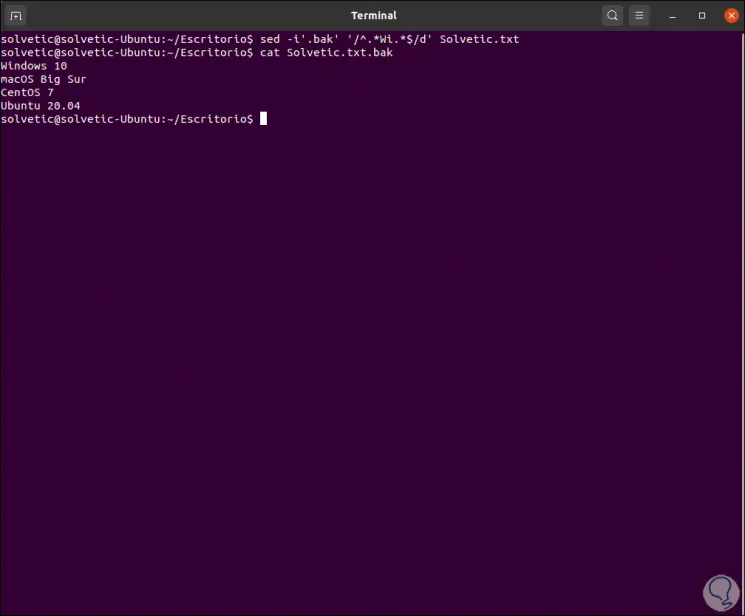
Step 2
It is possible to redirect the output to a new file with the same results:
sed -i'.bak '' /^.*Wi.*$/d 'TechnoWikis.txt> TechnoWikis1.txt
With sed we can work with the files in a completely complete way in Linux since we have seen each of its use options.