The operating systems are based on command lines that offer us multiple options to increase the distribution capabilities to be able to execute searches, administration actions, support and much more..
Just one of these options is linked to the possibility of searching for certain types of files in Linux and thus easily access their content and that is why today we will talk about pdfgrep which is focused on the search for PDF files .
What is pdfgrep
Pdfgrep is a command line utility to search text in PDF files in a simple and functional way saving us time to access each file and search the text with our own PDF tools.
Some of its features are:
- Compatible with Grep, we can execute many grep parameters such as -r, -i, -no -c.
- Ability to search text in multiple PDF files
- Featured colors, this GNU Grep color option is supported and enabled by default.
- Supports the use of regular expressions.
To keep up, remember to subscribe to our YouTube channel! SUBSCRIBE
1. Install Pdfgrep on Linux
Step 1
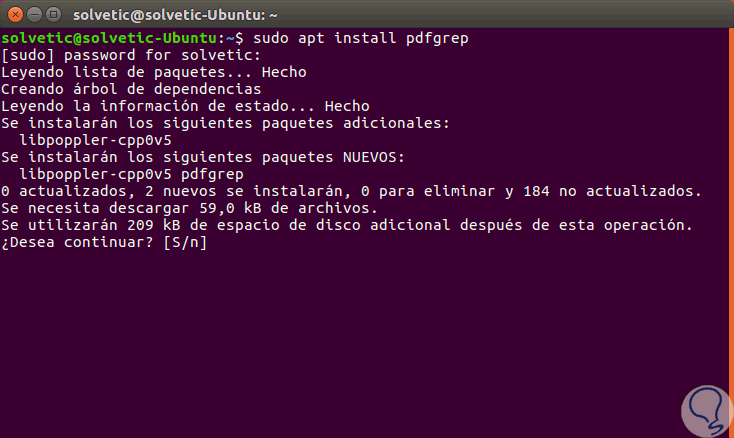
In this case we will use Ubuntu so it is enough to run the following line. There we enter the letter S to accept the download and installation of the packages.
sudo apt install pdfgrep
Step 2
Other installation options are:
- Download the .TAR.GZ file at the following link.
Pdfgrep
Step 3
- Or execute the following command:
git clone https://gitlab.com/pdfgrep/pdfgrep.git
Step 4
Then enter each of the following lines in your order:
./configure make sudo make install
2. Use Pdfgrep in Linux
Step 1
Once pdfgrep is installed, this will be the syntax to use:
pdfgrep [OPTION ...] PATTERN [FILE]
Step 2
Each of the elements are:
- Option: Indicates the attributes that we can add in the search, for example -i or --ignore-case , which ignore the distinction of upper and lower case letters between the pattern we have indicated and the one that should match the file.
- Pattern: Indicates an extended regular expression.
- File: It is the PDF file where the search is to be executed.
Step 3
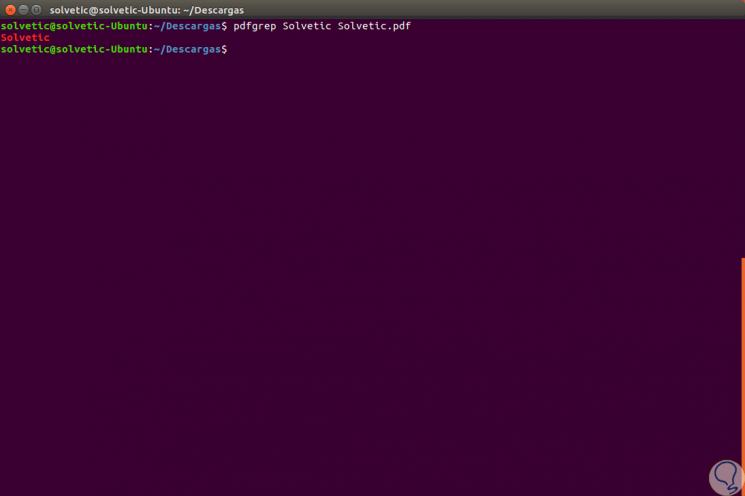
We will start with a simple search, for example, we will look for the word TechnoWikis in the file TechnoWikis.pdf, for this we execute the following:
pdfgrep TechnoWikis TechnoWikis.pdf
Step 4
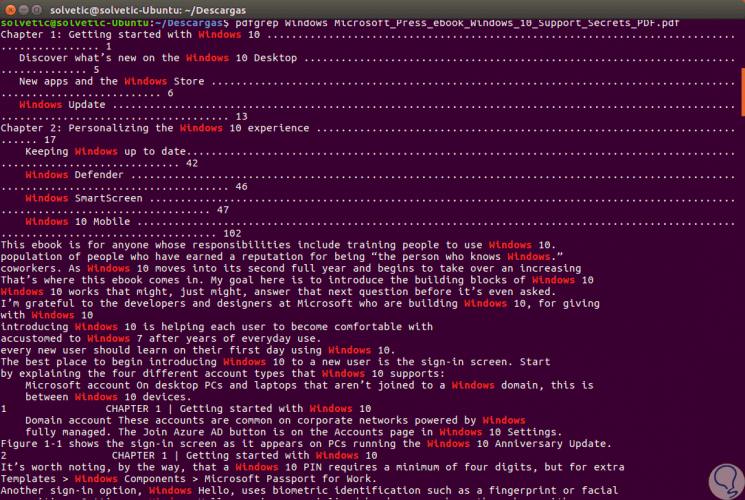
In this case there is only once this term in that file, but, now we will look for the term Windows in an official Microsoft PDF file and this will be the result we will see:
Step 5
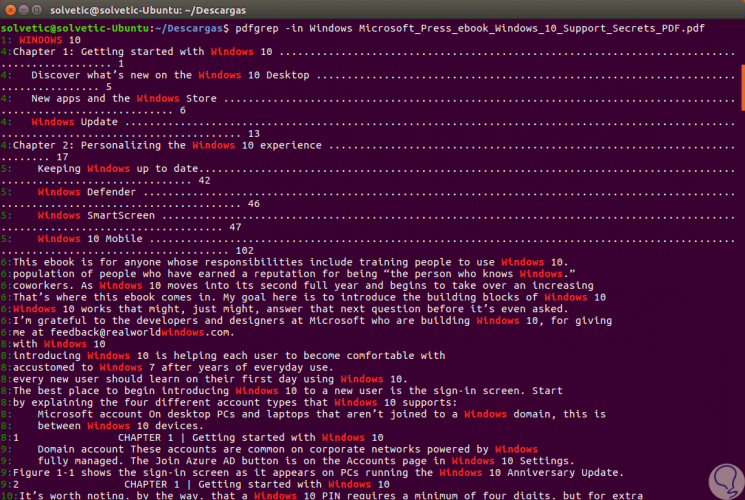
We can see that the searched word is highlighted which facilitates its location. Now, if we add the
-in parameter
, it will be possible to see the results with the page number where that term has been detected:
Step 6
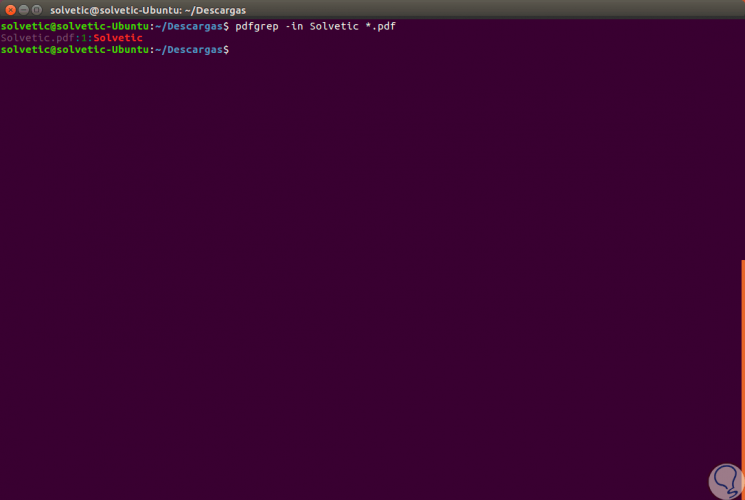
Another option that we can use with pdfgrep is to list the PDF file (s) that contain a certain term, for this we execute the following:
pdfgrep TechnoWikis * pdf
Step 7
In this way the PDF file where the term TechnoWikis is found will be listed:
Step 8
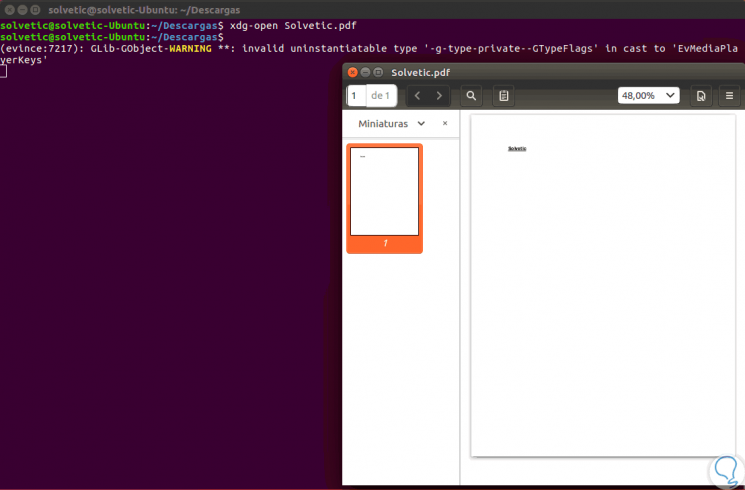
If we want to open the PDF file we can execute the following command:
xdg-open (File.PDF)
Step 9
The general options offered by pdfgrep are:
-i, --ignore-case
Ignore case distinctions both at the source and in the input files.
-F, --fixed-strings
Interpret PATTERN as a list of fixed chains separated by new lines.
--cache
Use a cache for the rendered text to speed up the operation on large files.
-P, --perl-regexp
Interpret PATTERN as a regular expression compatible with Perl (PCRE).
-H, --with-filename
Print the file name for each match.
-h, --no-file name
Deletes the file name prefix in the output.
-n, --page-number
Prefix each match with the page number where the search term was found.
-c, --count
Suppress normal output and, instead, print the number of matches for each input file.
-p, - Page Counting
Print the number of matches per page. It implies -n.
--color
It allows highlighting file names, page numbers and text matching different sequences to display them in color in the terminal, some of its options are Always, neck or automatic.
-o, --only-matching
Print only the coincident part of a line without any surrounding context.
-r, --recursive
It allows us to recursively search all files (restricted by --include and --exclude) under each directory, following symbolic links only if they are on the command line.
-R, - reference-recursive
Same as -r, but follow all symbolic links.
-quiet or -q
It allows us to exit the application.
With this pdfgrep becomes an ideal solution when working with PDF files in Linux environments..